

[ad_1]
Microsoft’s new generative AI model is leaner and more capable than even bigger language models.

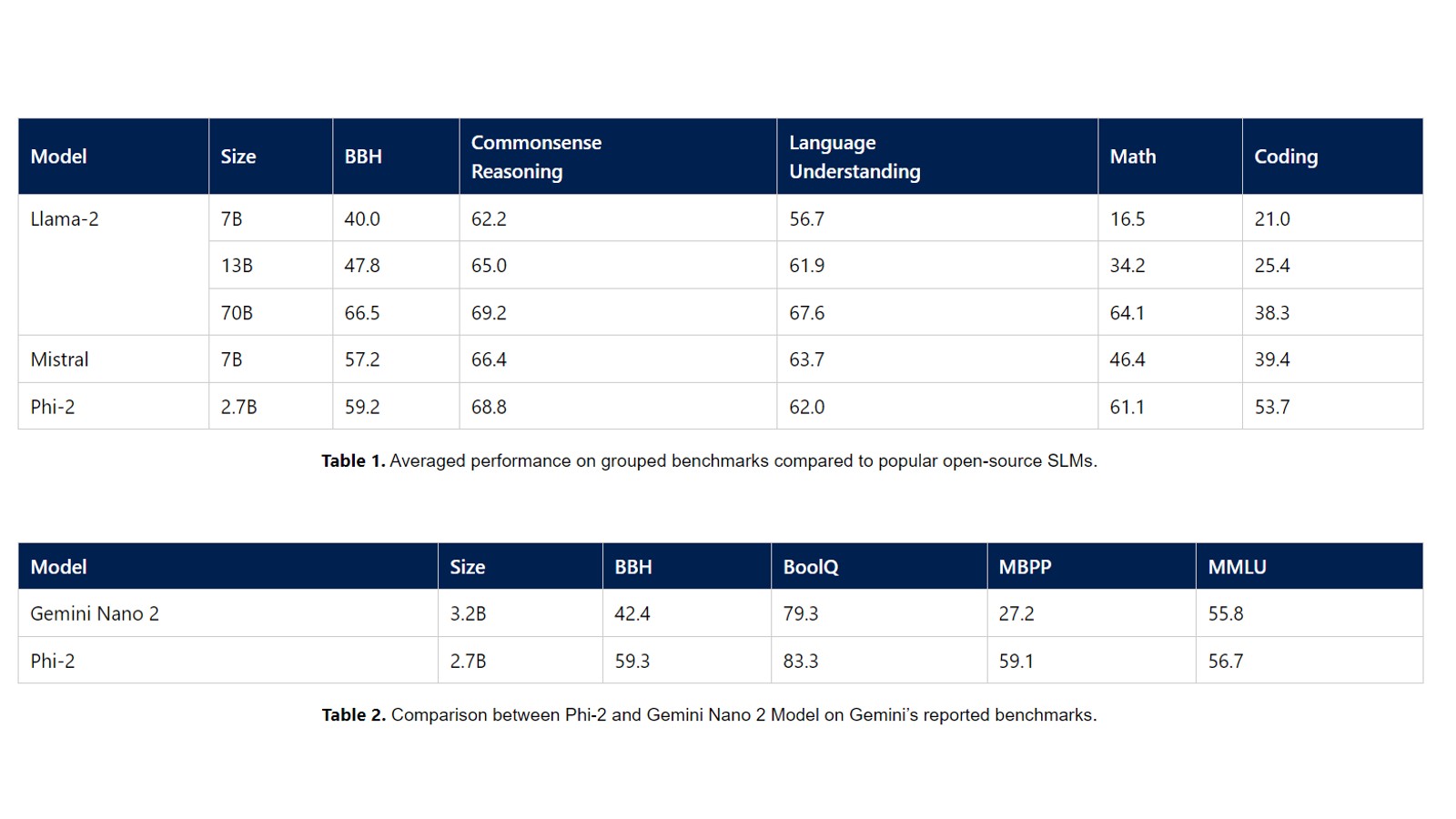
In the world of large language models (LLM) like GPT-4 and Bard, Microsoft has just released a new small language model—Phi-2, which has 2.7 billion parameters and is an upgraded version of Phi-1.5. Currently available via the Azure AI Studio model catalogue, Microsoft claims that Phi-2 can outperform larger models such as Llama-2, Mistral, and Gemini-2 in various generative AI benchmark tests.
Originally announced by Satya Nadella at Ignite 2023 and released earlier this week, Phi-2 was built by the Microsoft research team, and the generative AI model is said to have “common sense,” “language understanding,” and “logical reasoning.” According to the company, Phi-2 can even outperform models that are 25 times larger on specific tasks.

You have exhausted your
monthly limit of free stories.
Read more stories for free
with an Express account.
Continue reading this and other premium stories with an Express subscription. Use promo code EXPRESS to get 15% off.
This premium article is free for now.
Register to read more free stories and access offers from partners.
Continue reading this and other premium stories with an Express subscription. Use promo code EXPRESS to get 15% off.
This content is exclusive for our subscribers.
Subscribe now to get unlimited access to The Indian Express exclusive and premium stories.
Microsoft Phi-2 SLM is trained using “textbook-quality” data, which includes synthetic datasets, general knowledge, theory of mind, daily activities, and more. It is a transformer-based model with capabilities like a next-word prediction objective. Microsoft has trained Phi-2 on 96 A100 GPUs for 14 days, indicating that it is easier and more cost-effective to train this model on specific data compared to GPT-4. GPT-4 is reported to take around 90-100 days for training, using tens of thousands of A100 Tensor Core GPUs.

Microsoft’s Phi-2 can also solve complex mathematical equations and physics problems. On top of that, it can identify a mistake made by a student in a calculation.
On benchmarks like commonsense reasoning, language understanding, math, and coding, Phi-2 outperforms the 13B Llama-2 and 7B Mistral. Similarly, the model also outperforms the 70B Llama-2 LLM by a significant margin. Not just that, it even outperforms the Google Gemini Nano 2, a 3.25B model, which can natively run on Google Pixel 8 Pro.


A smaller model outperforming a large language model like Llama-2 has a huge advantage, as they cost a lot less to run with lower power and computing requirements. These are also models that can be trained for specific tasks and can easily run natively on the device, reducing output latency. Developers can access the Phi-2 model on Azure AI Studio.
© IE Online Media Services Pvt Ltd
First published on: 17-12-2023 at 11:28 IST
[ad_2]
Source link

